Делаю сложные задачи простыми решениями
- Город
- Москва
- Опыт работы
- 4 года
- На сайте с
- 2025 года
- Юридический статус
- Самозанятый
Клиенту нужно было регулярно собирать данные с сайтов конкурентов (цены, наличие, характеристики, ссылки на товары) и получать их в удобном формате для анализа и принятия решений. Ручной сбор занимал много времени, данные быстро устаревали, а источников было несколько.
Цель проекта — автоматизировать сбор данных и сделать систему, которая:
собирает информацию с нескольких сайтов
нормализует данные в единую структуру
сохраняет историю изменений (цены/наличие)
выгружает результат в Excel/CSV
работает стабильно даже при ограничениях на сайте (лимиты, капча, блокировки)
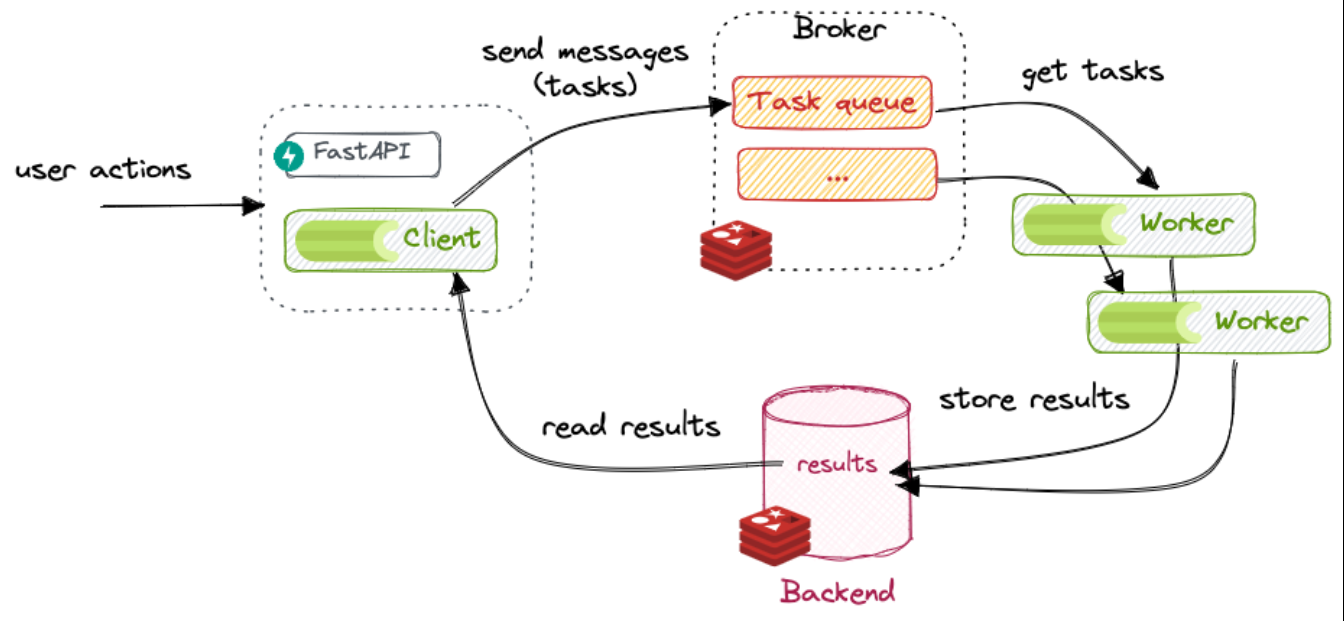
Я разработал парсер как сервис: он не просто «скрипт на коленке», а система с планировщиком, хранилищем и контролем качества данных.
Что сделал:
проанализировал структуру сайтов-источников и выбрал устойчивую стратегию парсинга (HTML/JSON/API, где доступно)
реализовал сбор данных по категориям и карточкам товаров, включая обработку пагинации
добавил нормализацию данных: приведение названий, валют, единиц измерения, чистка мусора
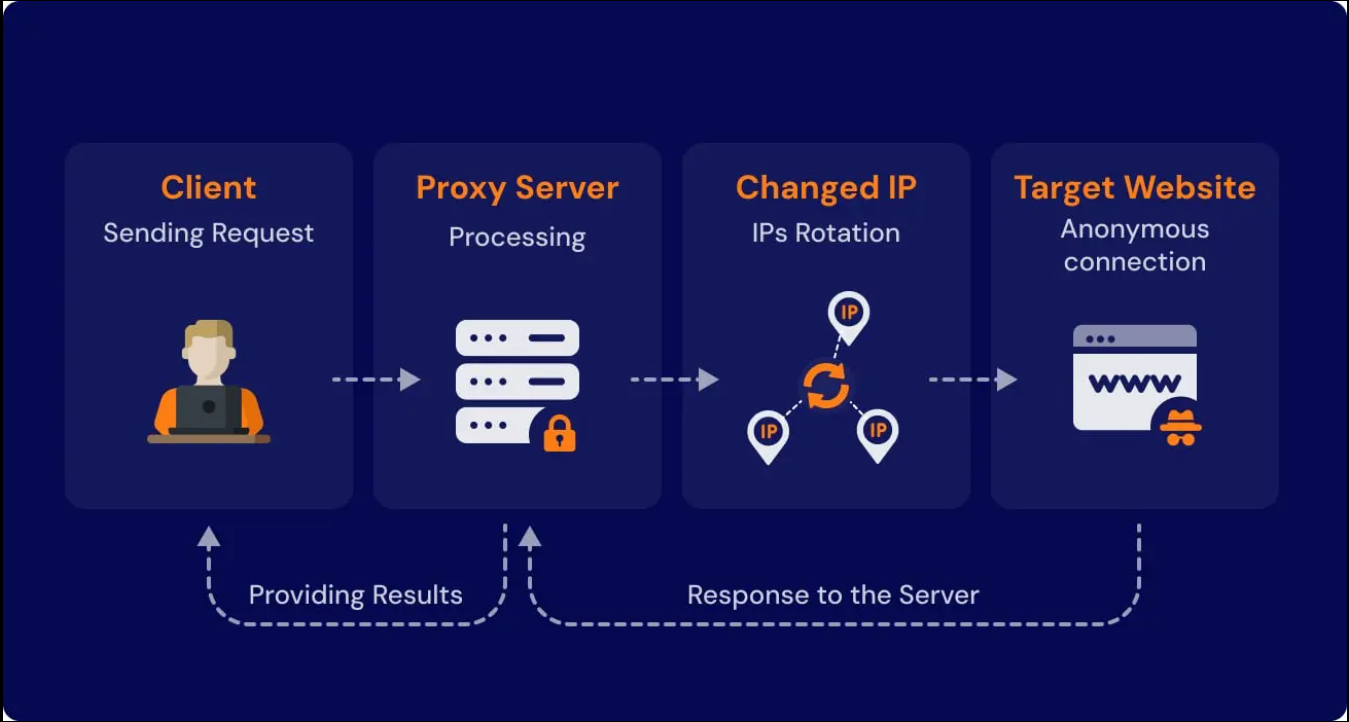
настроил антибан-механики: задержки, ротация User-Agent, прокси-пул, ретраи, ограничение частоты запросов
организовал очередь задач (чтобы парсер не падал при росте объёма)
сделал базу данных для хранения текущих значений и истории изменений
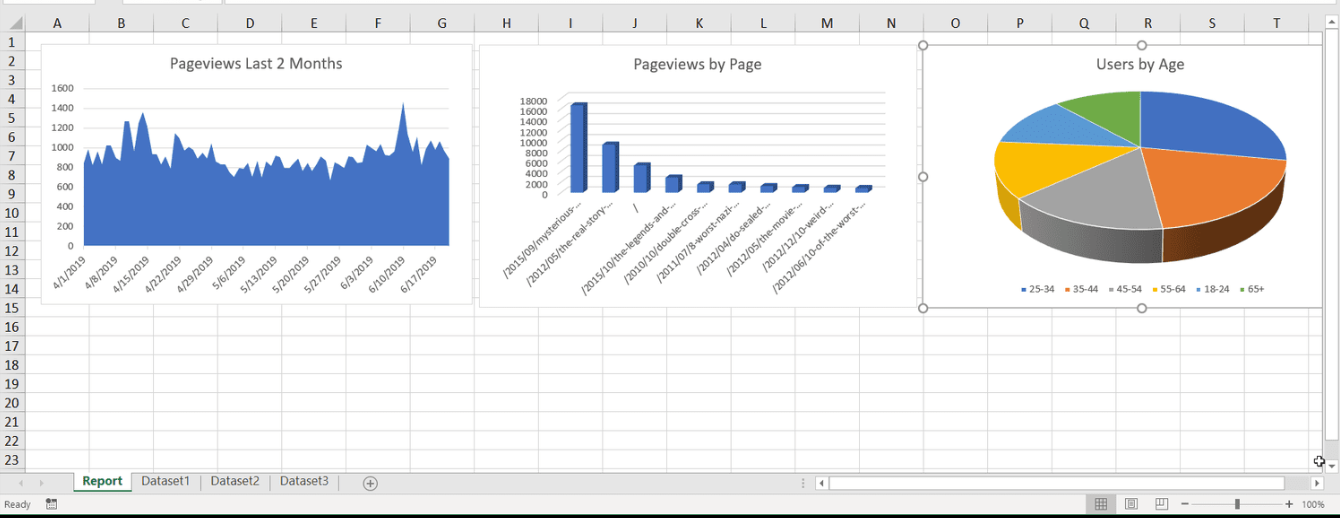
добавил автоматическую выгрузку в Excel/CSV по шаблону клиента
настроил запуск по расписанию и уведомления о сбоях/аномалиях (например, резкий обвал цен, пустые данные)
Клиент получил систему, которая ежедневно обновляет данные и выдаёт готовые отчёты без ручной работы.
Время на сбор информации сократилось с часов до минут
Данные стали актуальными и сравнимыми между разными источниками
Появилась история цен/наличия для аналитики и прогнозирования
Парсер работает стабильно при росте количества товаров и источников
Excel-выгрузка сразу подходит для отдела закупок/маркетинга и не требует ручной правки
Решение используется как инструмент мониторинга рынка и помогает быстрее принимать решения по ценам и ассортименту.