Автоматизация на стеке n8n/Make: боты любой сложности
- Опыт работы
- 3 года
- На сайте с
- 2026 года
- Юридический статус
- Самозанятый
Автоматизировать работу службы клиентской поддержки и отдела внутреннего обучения в крупной компании.
Контекст: На протяжении нескольких лет компания накопила колоссальный объем данных: технические регламенты, внутренние инструкции, спецификации оборудования и сотни PDF-файлов с обучающими материалами (суммарно более 500 документов).
Проблема: Сотрудники тратили от 10 до 20 минут на поиск конкретного ответа в массиве файлов, что замедляло работу поддержки и снижало качество обучения новичков. Традиционные поисковые системы по ключевым словам не справлялись с поиском по смыслу.
Цель: Разработать Telegram-бота на базе искусственного интеллекта, который способен мгновенно отвечать на вопросы сотрудников, используя исключительно базу знаний компании. Ключевое требование — полное исключение «галлюцинаций» ИИ (бот не должен придумывать информацию, которой нет в документах) и предоставление ссылок на первоисточники.
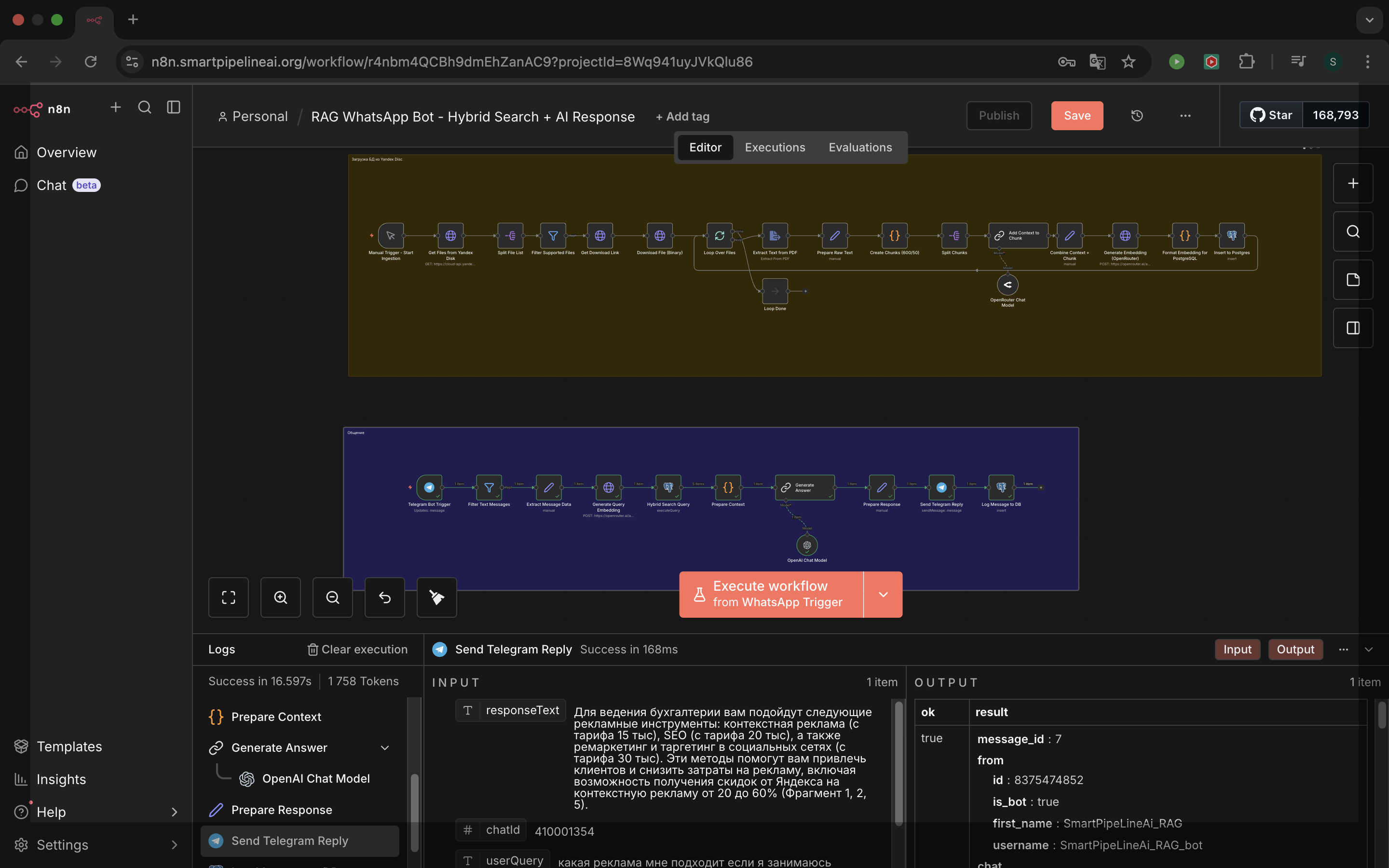
Для реализации проекта была выбрана архитектура RAG (Retrieval-Augmented Generation) на стеке n8n + Supabase + OpenAI, что позволило создать гибкую и масштабируемую систему без классического программирования.
Ход реализации:
Создание ETL-конвейера (n8n): Разработан автоматизированный сценарий, который парсит PDF-документы, очищает текст от «шума» и разбивает его на логические фрагменты (chunks) оптимального размера для сохранения контекста.
Векторизация данных: Интегрировано API OpenAI (модель text-embedding-3-small) для превращения текстовых фрагментов в математические векторы (эмбеддинги).
Архитектура хранения (Supabase): Настроена векторная база данных на базе PostgreSQL с расширением pgvector. Это позволило эффективно хранить тысячи векторов и выполнять по ним семантический поиск (поиск по близости смыслов).
Разработка логики «Поиск-Синтез»: * При поступлении вопроса бот сначала переводит его в вектор.
Выполняется поиск в Supabase 3–5 наиболее релевантных фрагментов текста.
Эти фрагменты передаются в модель GPT-4o вместе с вопросом и строгим системным промптом: «Используй только предоставленный текст. Если ответа нет — так и скажи. Не добавляй информацию от себя».
Оркестрация и интерфейс: В n8n настроен финальный воркфлоу, объединяющий прием сообщений из Telegram, обращение к базе данных и формирование ответа со ссылкой на название исходного документа и номер страницы.
Экономия времени: Среднее время поиска информации сократилось с 15 минут до 3–5 секунд.
Снижение нагрузки: Нагрузка на старших технических специалистов (L2/L3 поддержка) по типовым вопросам снизилась на 70%, так как рядовые сотрудники теперь получают ответы от ИИ-ассистента.
Точность: Благодаря строгой настройке контекста (RAG), бот выдает достоверные ответы со ссылками на пункты регламента, что критически важно для бухгалтерских и юридических процессов.
Масштабируемость: Система успешно прошла пилотный запуск и внедрена в ежедневную работу команды из 50+ человек. Стоимость содержания системы в разы ниже найма одного дополнительного сотрудника поддержки.