- Город
- Москва
- Опыт работы
- 4 года
- На сайте с
- 2006 года
- Юридический статус
- Самозанятый
Клиенту требовалось решение для быстрого и точного поиска по нормативно-правовым актам: федеральным законам, постановлениям Правительства, приказам регуляторов и другим документам.
Задача проекта — заменить ручной поиск по PDF и сайтам на удобный диалоговый интерфейс, который:
• понимает вопросы на естественном языке;
• находит релевантные фрагменты именно в законах и постановлениях;
• выдаёт краткий ответ строго на основе текста документов;
• всегда указывает источник: закон, статью, пункт, подпункт;
• исключает «галлюцинации» и вольные трактовки.
Проект ориентирован на юристов, специалистов по ИБ, комплаенс-офицеров и технических экспертов.
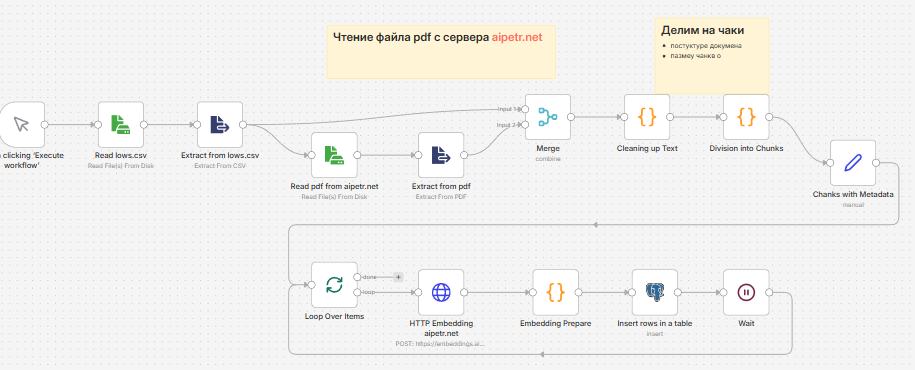
Решение реализовано как полноценная RAG-система (Retrieval-Augmented Generation) на базе n8n, Supabase, векторных эмбеддингов и LLM, с глубокой адаптацией под структуру нормативных документов.
Ключевые этапы реализации:
1. Загрузка и подготовка документов
Законы и постановления загружаются в формате PDF и CSV.
Текст автоматически:
o извлекается;
o очищается от служебного мусора;
o нормализуется (переносы строк, дефисы, пробелы).
2. Структурное разбиение (умный чанкинг)
Документы разбиваются не «по размеру», а по юридической структуре:
o раздел, статья, пункт, подпункт.
При этом:
o маленькие фрагменты автоматически объединяются;
o длинные — делятся по предложениям с overlap;
o сохраняется полный контекст документа.
3. Метаданные и ссылки
Для каждого чанка формируются метаданные:
o краткое название документа;
o статья, пункт, подпункт;
o версия документа;
o человекочитаемая ссылка вида 187-ФЗ · ст. 2 · п. 7.
4. Построение эмбеддингов
Каждый чанк преобразуется в embedding и сохраняется в базе данных.
Это позволяет выполнять быстрый семантический поиск по смыслу, а не по ключевым словам.
5. Гибридный поиск
Поиск выполняется комбинированно:
o векторное сходство (semantic search);
o ключевые слова (keyword search).
Веса автоматически меняются в зависимости от длины и типа запроса.
6. Агрегация и ранжирование
Результаты:
o сортируются по combined score;
o отфильтровываются по порогу релевантности;
o отбираются только 1–2 самых точных фрагмента.
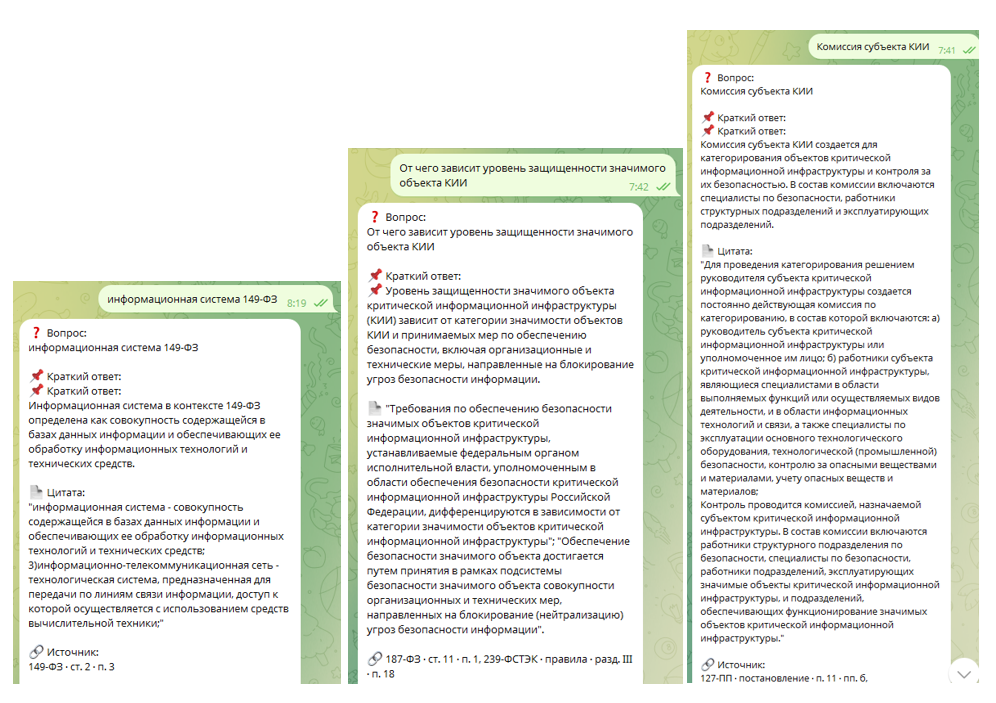
7. Генерация юридически корректного ответа
AI-модель работает в строгом режиме:
o отвечает только на основе контекста;
o использует ограниченное число цитат;
o не додумывает и не интерпретирует текст.
Формат ответа:
o краткий вывод;
o дословная цитата;
o точный источник.
8. Интерфейс пользователя
Реализован Telegram-бот:
o показывает сообщение ожидания;
o возвращает аккуратно отформатированный ответ;
o подходит для ежедневной практической работы.
Вся система построена с учетом расширение базы документов и подключение новых отраслей законодательства.
В результате клиент получил интеллектуальный инструмент, который:
• быстро ищет ответы в законах и постановлениях;
• понимает вопросы на естественном языке;
• всегда ссылается на конкретные нормы;
• снижает риск ошибок и неверных трактовок;
• экономит часы работы специалистов.
Практическое применение:
• юридические и комплаенс-подразделения;
• специалисты по информационной безопасности;
• внутренние базы знаний организаций;
• корпоративные AI-ассистенты без передачи данных наружу.