- Город
- Москва
- Опыт работы
- 4 года
- На сайте с
- 2006 года
- Юридический статус
- Самозанятый
Клиенту требовалось решение для поиска информации и получения ответов по внутренним документам организации в формате диалога.
Документы хранятся локально (регламенты, инструкции, методички, техническая документация) и недоступны для публичных AI-сервисов.
Цель проекта — создать AI-поисковик, который:
• понимает вопросы на естественном языке;
• ищет ответы только во внутренней базе документов;
• выдаёт краткий и точный ответ с опорой на конкретные фрагменты;
• исключает «галлюцинации» и ответы вне источников;
• работает через привычный интерфейс (Telegram).
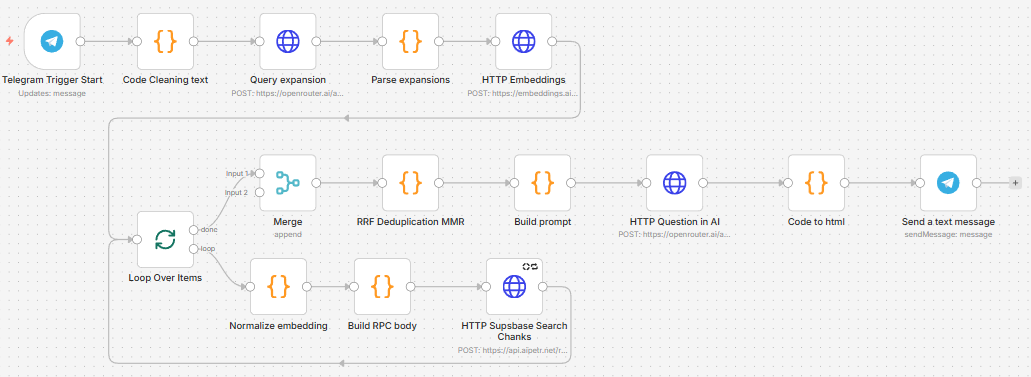
Проект реализован как RAG-система с использованием n8n, Supabase, векторных эмбеддингов и LLM.
Ключевые этапы и архитектура решения:
1. Приём и нормализация запроса
Пользователь задаёт вопрос в Telegram.
Запрос очищается от эмодзи, мусорных символов, нормализуется регистр и формируется базовый поисковый текст.
2. Расширение запроса (Query Expansion)
AI-модуль генерирует несколько семантически близких вариантов запроса.
Это позволяет повысить полноту поиска и находить релевантные фрагменты даже при разных формулировках.
3. Построение эмбеддингов
Каждый вариант запроса преобразуется в вектор с помощью отдельного embedding-сервиса для векторного поиска.
4. Векторный поиск по базе документов
Поиск выполняется через RPC-функцию Supabase (match_doc_chunks), которая возвращает наиболее близкие фрагменты документов (чанки) с метаданными:
o документ;
o номер страницы;
o номер чанка;
o коэффициент сходства.
5. Агрегация и дедупликация результатов
Результаты от разных вариантов запроса объединяются с помощью:
o RRF (Reciprocal Rank Fusion) — для повышения стабильности;
o MMR (Maximal Marginal Relevance) — для снижения дублирования и повышения разнообразия контекста.
6. Контроль уверенности
Если релевантность найденных фрагментов ниже заданного порога, система честно сообщает, что данных недостаточно для ответа.
7. Генерация ответа
LLM получает строго ограниченный контекст из 1–3 наиболее релевантных фрагментов и формирует:
o краткий связанный ответ;
o без использования внешних знаний;
o без выдумывания информации вне документов.
8. Отправка результата пользователю
Финальный ответ возвращается в Telegram в читаемом виде (HTML), готовый для практического использования сотрудниками.
Вся логика реализована в виде прозрачного и расширяемого workflow в n8n.
В результате клиент получил AI-систему, которая:
• ищет информацию по локальным документам организации;
• отвечает на вопросы на естественном языке;
• опирается только на проверенные внутренние источники;
• снижает нагрузку на сотрудников и службу поддержки;
• масштабируется под новые документы и отделы.
Практическое применение:
• внутренний AI-помощник для сотрудников;
• поиск по регламентам, инструкциям и законам;
• корпоративная база знаний с диалоговым интерфейсом;
• основа для безопасных AI-решений без передачи данных наружу.