- Город
- Нижний Новгород
- Опыт работы
- 11 лет
- На сайте с
- 2026 года
- Юридический статус
- Самозанятый
HR-агентство работает через Telegram: резюме кандидатов падают в группы вперемешку — текстом, PDF, DOCX, фотографиями и сканами; вакансии собираются из своих и партнёрских каналов. Чтобы предложить кандидата нанимателю, рекрутер вручную открывает каждое резюме, вытаскивает роль, грейд, стек и опыт и сопоставляет с открытыми вакансиями. На потоке это не масштабируется: разнобой форматов (фото и скан вообще не попадают в поиск), ручное сопоставление каждого резюме с каждой вакансией, дубли из пересекающихся каналов. Это типичная боль рекрутингового агентства или внутреннего HR с входящим потоком резюме из мессенджеров.
Цель — конвейер «от сообщения в Telegram до готовой пары кандидат–вакансия в дашборде», где человеку остаётся модерация, а не ручной разбор.
Собрал под ключ всю систему — сбор, ИИ-парсинг, матчинг, фронтенд, инфраструктуру. Один ответственный за весь стек.
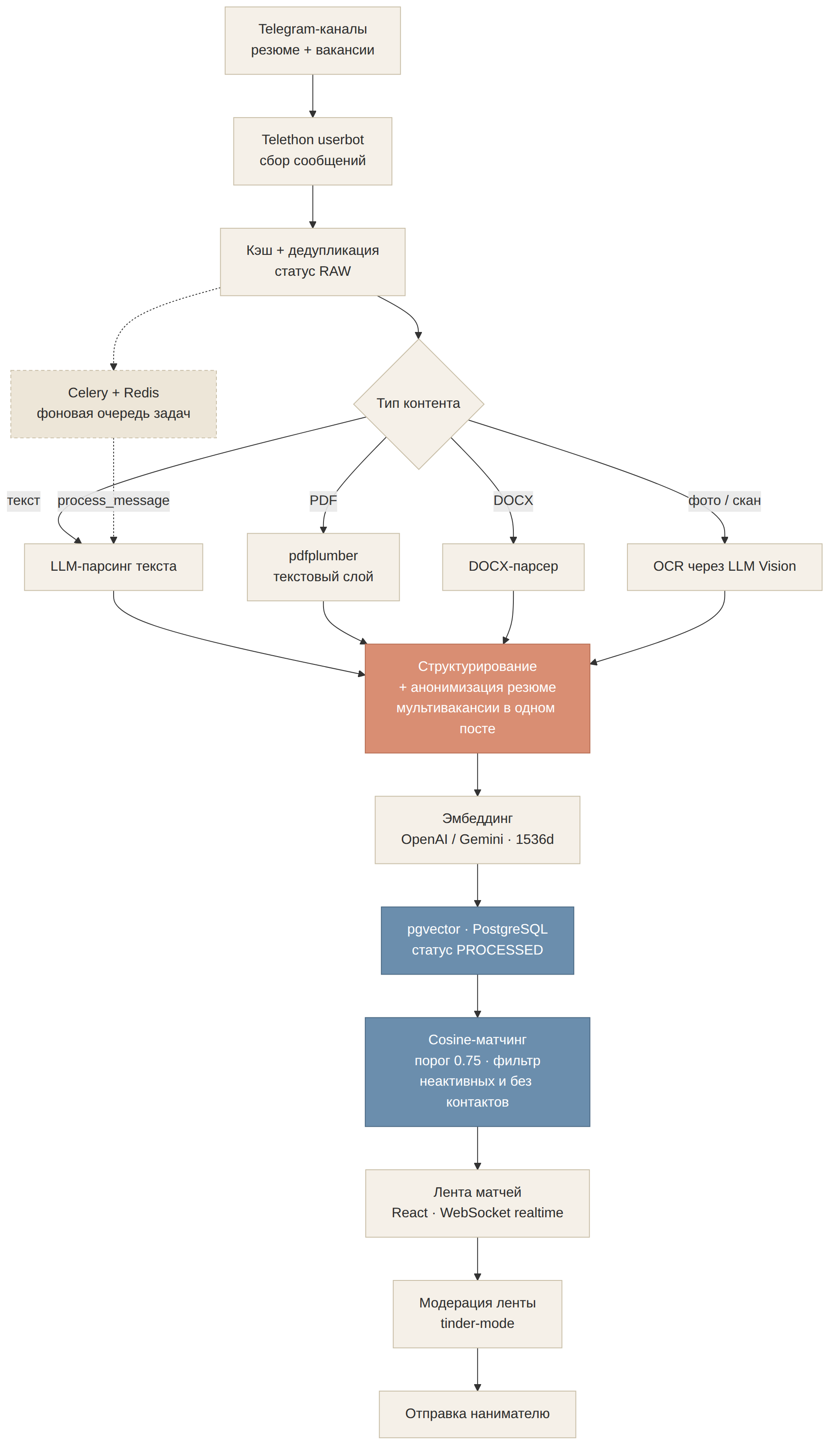
Сбор. Userbot на Telethon слушает каналы с резюме и каналы с вакансиями, складывает входящие со статусом RAW, проверяет кэш и отсекает дубли из пересекающихся источников ещё до обработки.
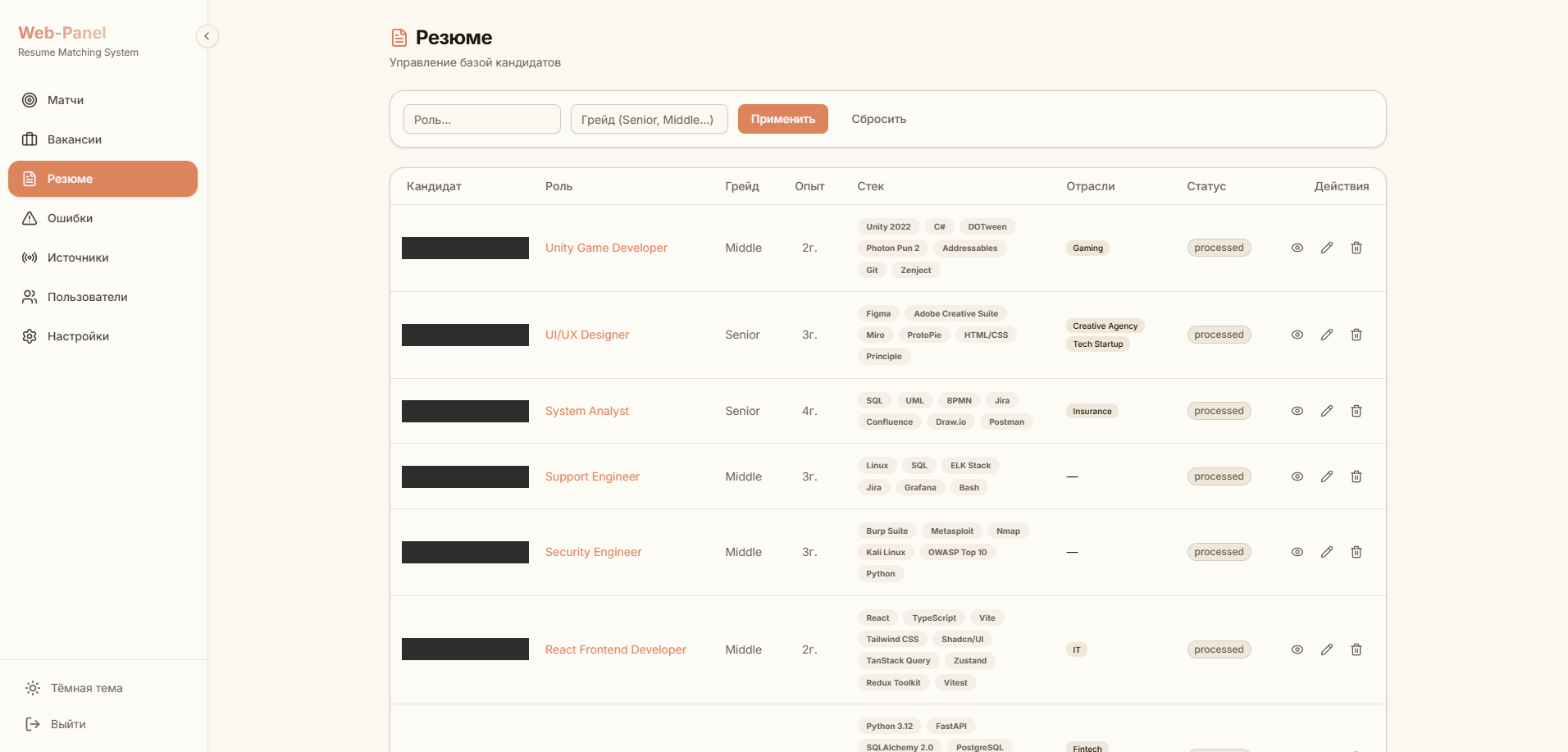
Парсинг любых форматов. Тип контента определяется автоматически: текст идёт в LLM напрямую, текстовый слой PDF снимается через pdfplumber, DOCX — своим парсером, фото и сканы (где текстового слоя нет) распознаются OCR через LLM Vision. Дальше LLM (OpenAI / Gemini) приводит сырой текст к единой структуре — роль, грейд, стек, опыт — и на этом же шаге анонимизирует резюме (вычищает прямые контакты): privacy-by-design. Один пост может содержать несколько вакансий — парсер их разделяет.
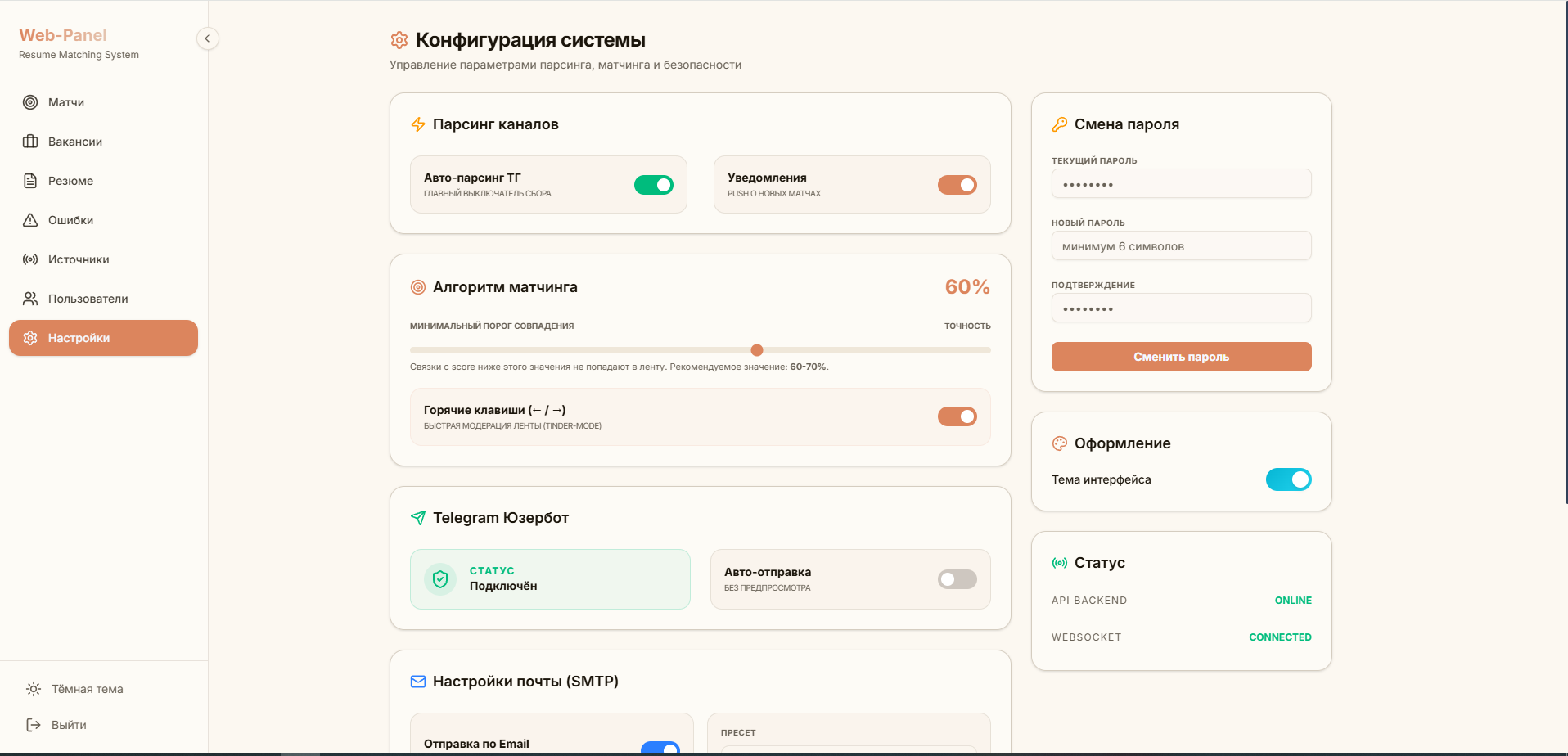
Матчинг — векторный, не по ключевым словам. Из структурированных полей генерируется эмбеддинг (1536d) и хранится в pgvector внутри PostgreSQL; пары ищутся по косинусному расстоянию с настраиваемым порогом (по умолчанию 0.75), фильтр отсекает неактивные вакансии и вакансии без контактов. «Python-разработчик» и «бэкендер на FastAPI» по ключевым словам не совпадут, по смыслу — близки.
Фон и реалтайм. Тяжёлая обработка вынесена в Celery + Redis, дашборд получает новые матчи по WebSocket без перезагрузки. Статусы RAW → PROCESSED; при ошибке — ERROR с сохранением исходного файла для разбора, а не молчаливая потеря.
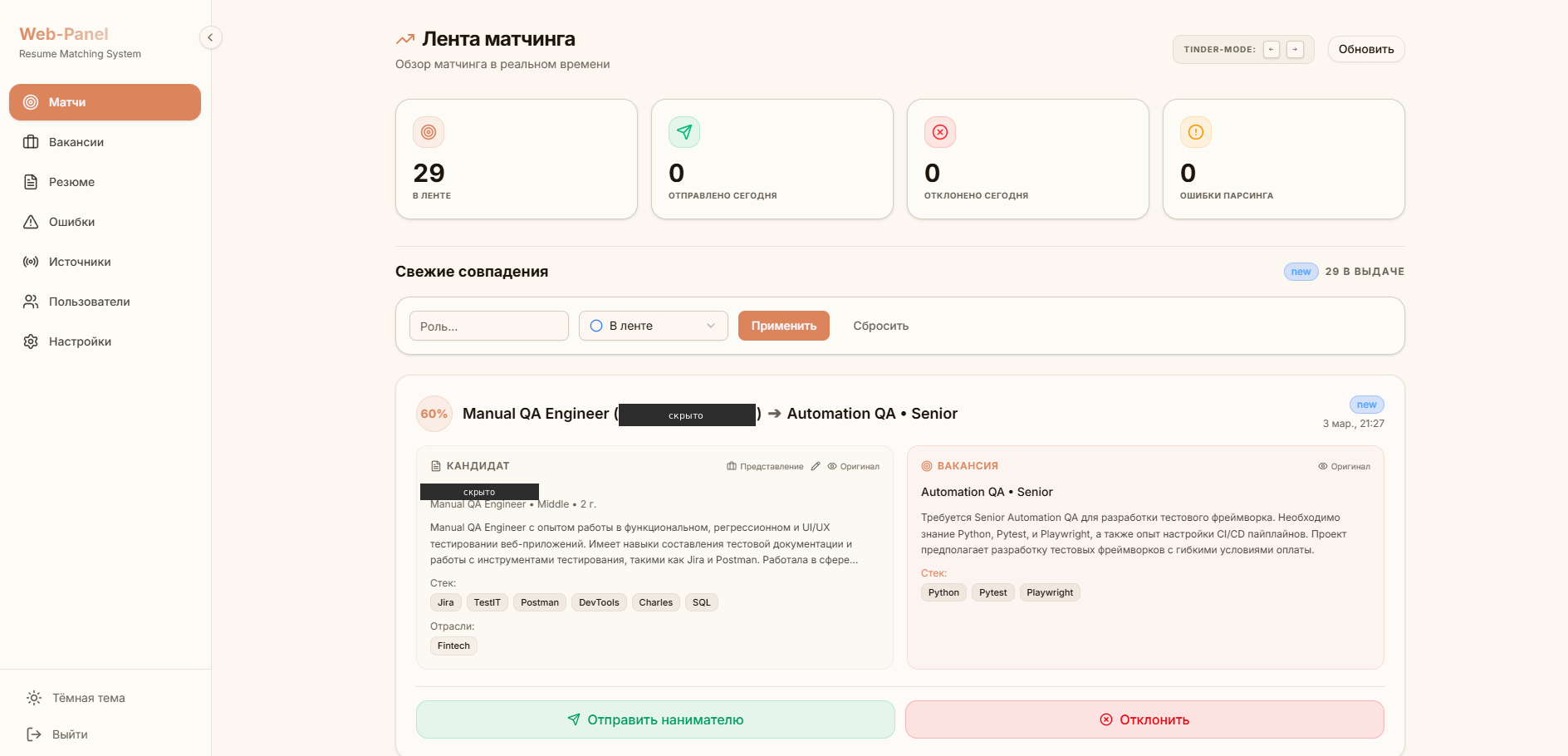
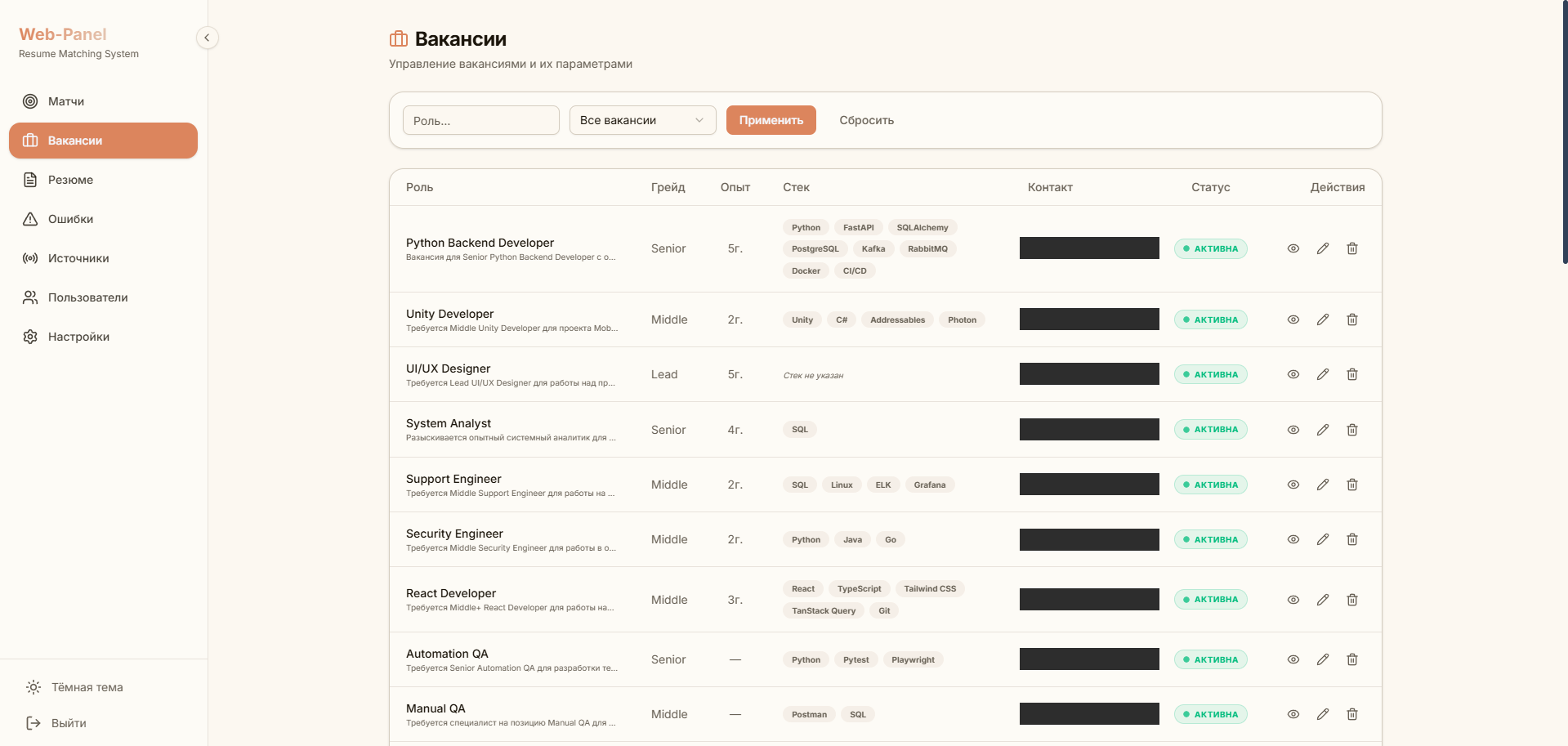
Дашборд. На React 19 — лента матчей со score, карточки «кандидат | вакансия» рядом, быстрая модерация горячими клавишами (tinder-mode ← / →) и отправка нанимателю в один шаг. Дизайн UI спроектировал и собрал сам, без отдельного дизайнера.
Девопс. Контейнеризация Docker + nginx, CI/CD на GitLab, 304 pytest-теста (инфраструктура и БД, Telegram и API, парсинг и OCR, матчинг и вектор, end-to-end).
Резюме любого формата — текст, PDF, DOCX, фото, скан — приводится к единой структуре и попадает в поиск (раньше скан-фото не искалось вообще); матчинг по смыслу с настраиваемым порогом; реалтайм-лента с модерацией в один клик (tinder-mode); дубли из пересекающихся каналов отсекаются на входе. 304 теста, контейнеризация, CI/CD — production-уровень, а не прототип «на коленке».
Оценочно, по индустриальным нормам 2026 (SHRM, McKinsey, LinkedIn): ручной первичный разбор и сопоставление одного резюме — около 5 минут, пачка из 100 резюме — 12–18 часов, ручной throughput — 6–10 разборов в день. Конвейер сводит разбор к секундам на резюме, а человеку остаётся модерация уже готовой ленты пар.
Отправка нанимателю — через подтверждение человеком: пара уходит кандидату только после проверки (human-in-the-loop). Сбор заточен под Telegram-источники, под другой канал (почта, биржи) добавляется коннектор.