AI-интеграции и разработка сложных решений под ключ
- Город
- Москва
- Опыт работы
- 23 года
- На сайте с
- 2018 года
- Юридический статус
- Самозанятый
Решение
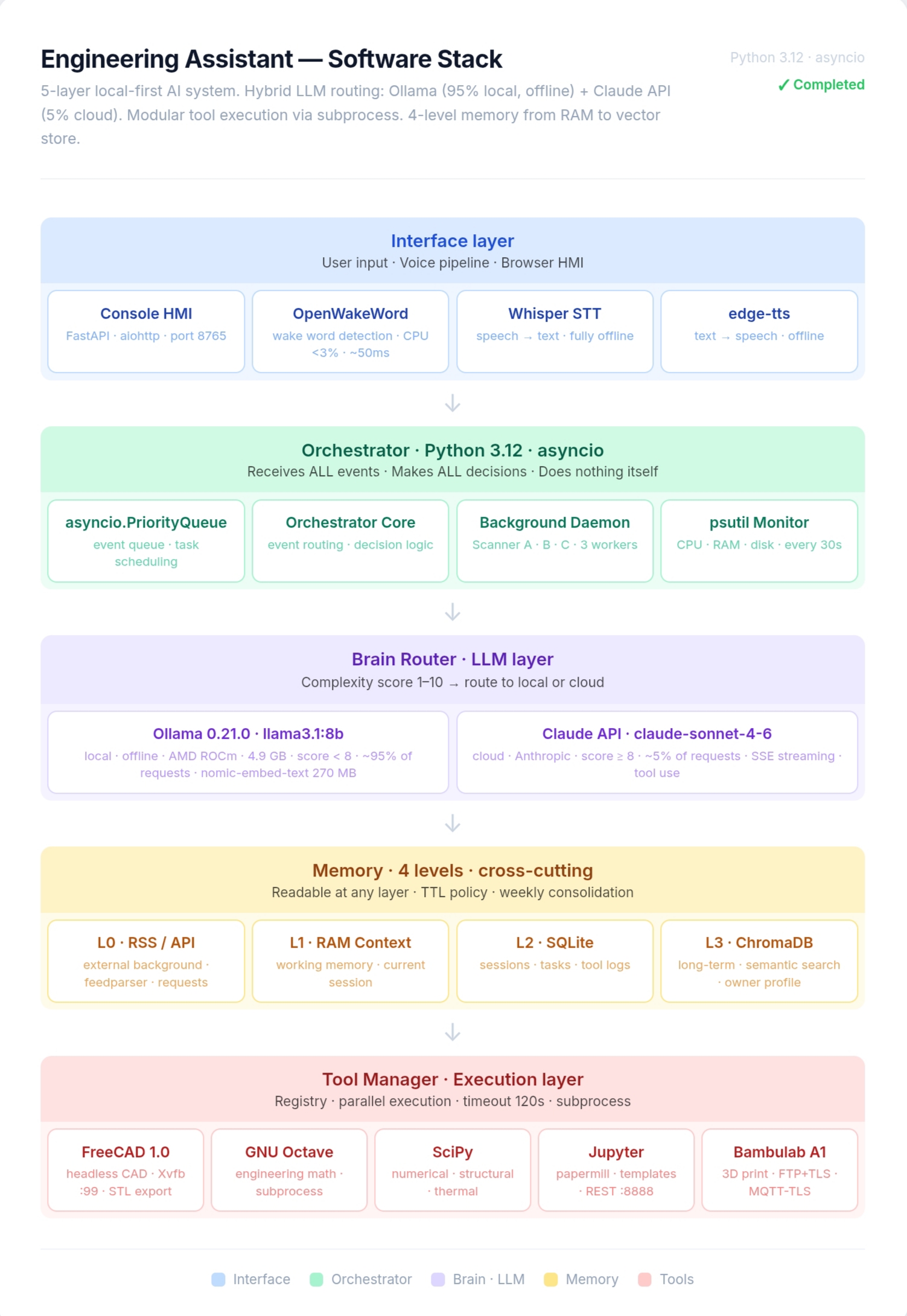
1. Архитектура под инженерные задачи
Спроектирована 5-слойная система: интерфейс, оркестратор, LLM-маршрутизатор, многоуровневая память и слой выполнения инструментов. Каждый слой независим — замена модели или добавление нового инструмента не затрагивает остальные компоненты. Основной принцип: ассистент не выполняет задачи сам — он управляет специализированными инженерными инструментами.
2. Голосовой интерфейс и ввод
Реализован полноценный голосовой pipeline: OpenWakeWord — детекция wake-слова с нагрузкой на CPU менее 3% и задержкой ~50 мс, Whisper STT — распознавание речи полностью офлайн, edge-tts — синтез ответа. Параллельно доступен Console HMI через FastAPI/aiohttp на порту 8765. Система принимает команды голосом во время работы за CAD или расчётами — руки остаются свободными.
3. Гибридная маршрутизация LLM
Оркестратор на Python 3.12 + asyncio оценивает каждый запрос по шкале 1–10. Оценка ниже 8 — локальная модель Ollama 0.21.0 (llama3.1:8b, AMD ROCm, 4.9 ГБ, офлайн). Оценка 8 и выше — Claude API (claude-sonnet-4-6) с SSE-стримингом и вызовом инструментов. Около 95% инженерных запросов — типовые расчёты, уточнения параметров, генерация скриптов — обрабатываются локально без интернета и без затрат.
4. Слой инженерных инструментов
Tool Manager управляет параллельным запуском специализированного ПО через subprocess с таймаутом 120 секунд:
— FreeCAD 1.0 в headless-режиме (Xvfb :99) — генерация и экспорт 3D-моделей в STL по голосовой или текстовой команде
— GNU Octave — инженерные математические расчёты
— SciPy — численные методы, структурный и тепловой анализ
— Jupyter через papermill — выполнение расчётных шаблонов, REST-интерфейс на порту 8888
— Bambulab A1 — отправка моделей на 3D-печать по FTP+TLS и управление через MQTT-TLS
5. Четырёхуровневая память
L0 — внешние RSS и API-фиды (актуальные данные материалов, стандартов); L1 — RAM-контекст текущей сессии; L2 — SQLite с логом сессий, задач и вызовов инструментов; L3 — ChromaDB с семантическим поиском и профилем владельца (nomic-embed-text, 270 МБ). TTL-политика и еженедельная консолидация не дают базе расти бесконтрольно.
1. Проектирование архитектуры
До написания первой строки кода была спроектирована 5-слойная архитектура: интерфейс, оркестратор, LLM-модуль, система памяти и слой выполнения инструментов. Каждый слой изолирован — его можно заменить или расширить без изменения остальных. Такое решение принято осознанно: системы с монолитной AI-логикой быстро накапливают технический долг при смене модели или добавлении нового провайдера. Здесь этого нет.
2. Гибридная маршрутизация LLM
Центральный элемент системы — scoring-модуль, который оценивает каждый входящий запрос по шкале от 1 до 10. В расчёт берутся: сложность формулировки, длина и вложенность контекста, тип задачи (генерация, reasoning, поиск, суммаризация). Запросы с оценкой ниже 8 направляются в локальную модель — Ollama с llama3.1:8b, запущенную на AMD GPU с поддержкой ROCm. Работает офлайн, без задержек сети, без затрат. Запросы от 8 и выше передаются в Claude API — только там, где локальная модель объективно проигрывает по качеству. Порог подобран эмпирически на реальных диалогах: около 95% запросов обрабатывается локально. Расходы на облачный API в ежедневном использовании снижены практически до нуля.
3. Четырёхуровневая система памяти
Память реализована как стек из четырёх независимых уровней с разным горизонтом хранения:
— RAM-кэш — рабочий контекст текущей сессии. Мгновенный доступ, никакого дискового I/O.
— SQLite — персистентный лог диалогов. Позволяет восстанавливать сессии после перезапуска и анализировать историю взаимодействий.
— ChromaDB — долгосрочное векторное хранилище. Эмбеддинги строятся через nomic-embed-text. При каждом запросе система ищет семантически близкий контекст из прошлых разговоров и подставляет его в промпт — ассистент «помнит» без переобучения модели.
— Внешние RSS и API-фиды — источники актуальных данных в реальном времени. Модель получает свежую информацию без необходимости обновления весов.
Такая структура позволяет ассистенту работать с долгосрочным контекстом и оставаться актуальным без облачных зависимостей.
4. Оркестрация и слой инструментов
Оркестратор управляет последовательностью обработки каждого запроса: сначала извлекается релевантный контекст из памяти, затем при необходимости вызываются внешние инструменты (поиск, файловая система, API), и только после этого запрос передаётся в LLM. Это снижает нагрузку на модель, уменьшает длину промптов и ускоряет итоговый ответ.
5. Инфраструктура
Вся система запускается через Docker Compose. Ollama, ChromaDB и основное приложение изолированы в отдельных контейнерах. Настроены автозапуск при старте системы, структурированное логирование и healthcheck для каждого сервиса. Решение полностью локальное — никаких облачных зависимостей в базовом режиме работы.
Полноценная инженерная рабочая среда с голосовым управлением
Ассистент закрывает полный цикл: голосовая постановка задачи → расчёт (SciPy / Octave) → генерация модели (FreeCAD) → печать (Bambulab A1). Все этапы управляются через единый интерфейс без переключения между программами.
Скорость и автономность
Система работает полностью офлайн. Никакой зависимости от облака для стандартных инженерных задач. Wake-слово — 50 мс, STT — локально, расчёты — локально. Интернет нужен только для ~5% запросов, требующих сложного рассуждения.
Конфиденциальность проектных данных
Чертежи, параметры изделий, расчёты — ничего не покидает машину. Критично для разработки, где данные нельзя передавать в облако.
Накопление инженерной базы знаний
ChromaDB накапливает контекст: прошлые расчёты, параметры материалов, решения по конкретным проектам. Со временем ассистент точнее предлагает решения, опираясь на собственный опыт работы с владельцем.
Применение
Личный инженерный стенд для проектирования, прототипирования и расчётов. Основа для тиражируемого решения: производственные компании, конструкторские бюро, инженеры-одиночки с потребностью в автоматизации рутины без облачных подписок.