Тюмень
Паспорт верифицирован
Всего отзывов:
1
0
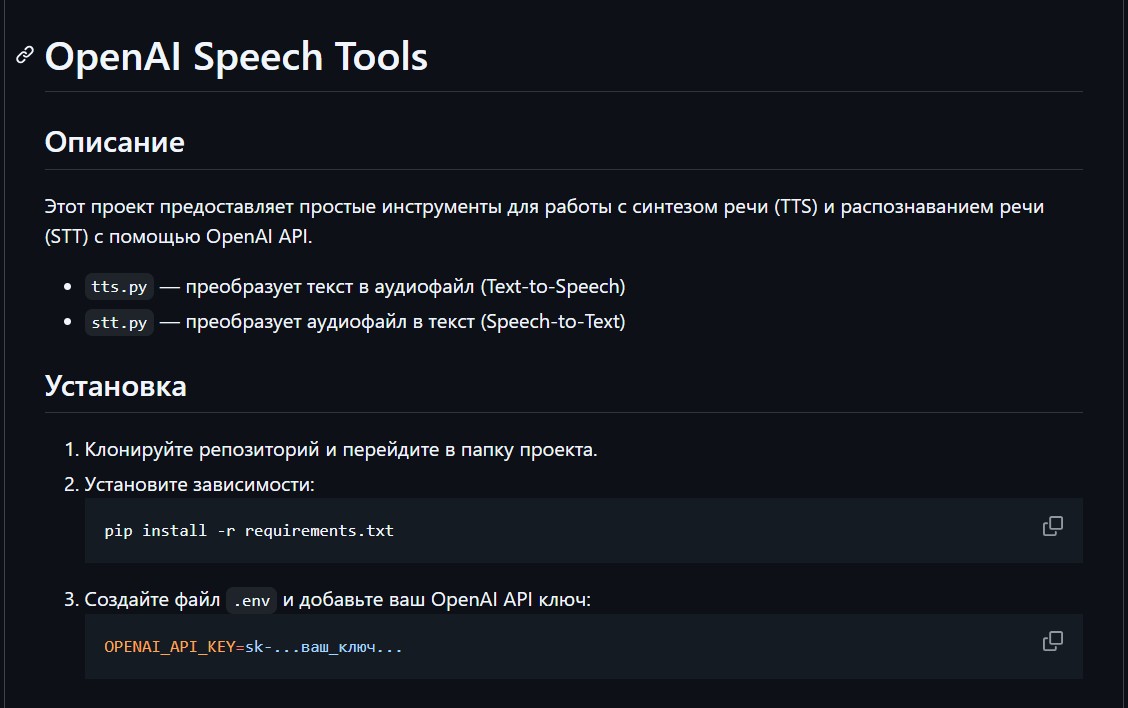
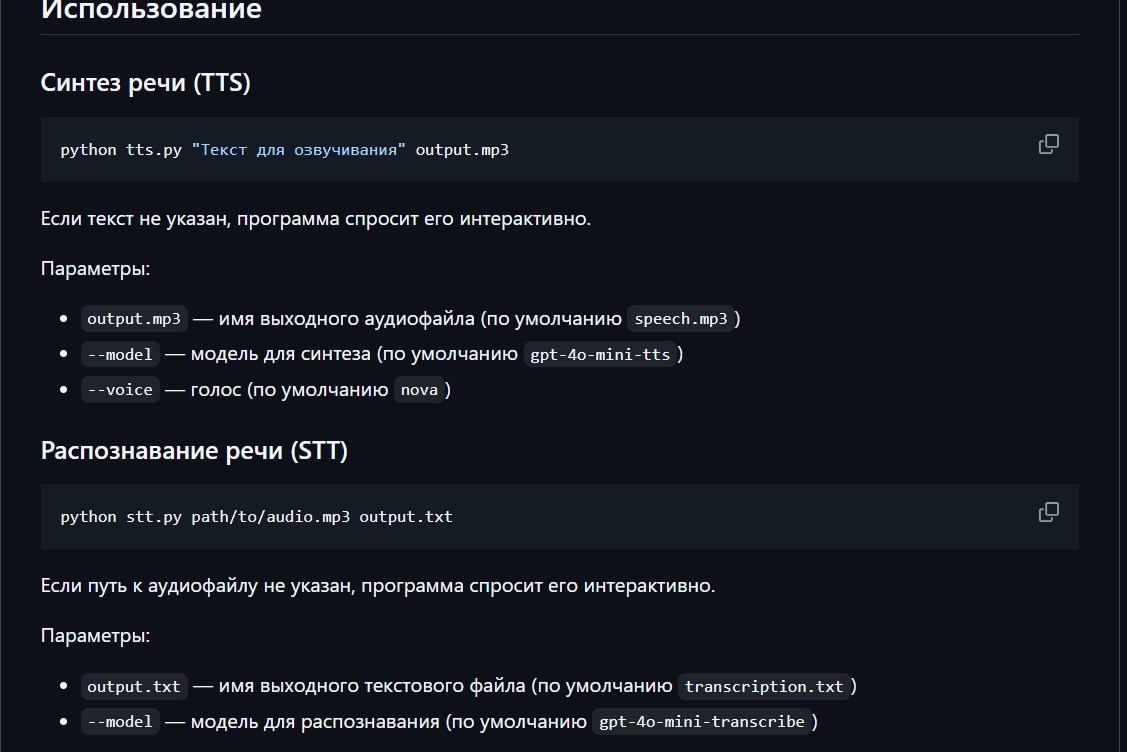
 и распознаванием речи (STT) с использованием OpenAI")