Python разработка для ваших целей
- Город
- Самара
- Опыт работы
- 4 года
- На сайте с
- 2025 года
- Юридический статус
- Самозанятый
Безопасная сделка
Деньги списываются после приёмки
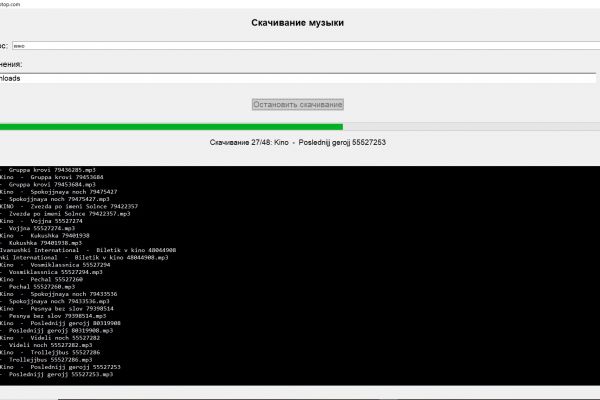
Данный проект представляет собой разработку автоматизированного решения для сбора и структурирования данных из каталогов товаров, размещенных на маркетплейсе Яндекс Маркет. Приложение позволяет извлекать ключевую информацию о различных категориях товаров, представленных на торговой площадке, и сохранять ее в удобных форматах для дальнейшего анализа.
Для реализации проекта был использован следующий стек технологий:
Python - основной язык программирования
Selenium - библиотека для автоматизации взаимодействия с веб-браузером
BeautifulSoup - библиотека для парсинга HTML-документов
XLSX - формат для экспорта данных в электронные таблицы
JSON - формат для хранения и передачи данных
Основные компоненты и функциональность приложения:
Модуль для взаимодействия с веб-сайтом Яндекс Маркет с использованием Selenium.
Парсер HTML-кода, построенный на базе BeautifulSoup, для извлечения необходимой информации о товарах (название, описание, цена, изображения и т.д.).
Механизм экспорта данных в формате XLSX (электронные таблицы) и JSON для последующего анализа и использования.
Обработка различных сценариев, таких как обработка ошибок, пагинация каталога, загрузка изображений.
В результате выполнения проекта было создано приложение для парсинга каталогов Яндекс Маркет, которое:
Автоматизирует процесс сбора информации о товарах, представленных на торговой площадке
Структурирует собранные данные в удобных форматах (XLSX, JSON)
Обеспечивает гибкость и масштабируемость за счет использования модульной архитектуры
Демонстрирует применение современных Python-библиотек, таких как Selenium и BeautifulSoup, для решения задач веб-скрапинга